|
Sayan Rakshit
I am a Ph.D. student at Indian Institute of Technology Bombay. Prof. Biplab Banerjee is my Ph.D. superviser.
My research interest include computer vision and deep learning, specifically, domain adaptation, Incremental learning, Few-shot learning, image and video synthesis and editing using generative models.
Email | GitHub | Google Scholar | LinkedIn |

|

IIT Bombay |

Honda R&D, Tokyo |

Adobe |

Inria -Nice |
Research |
|
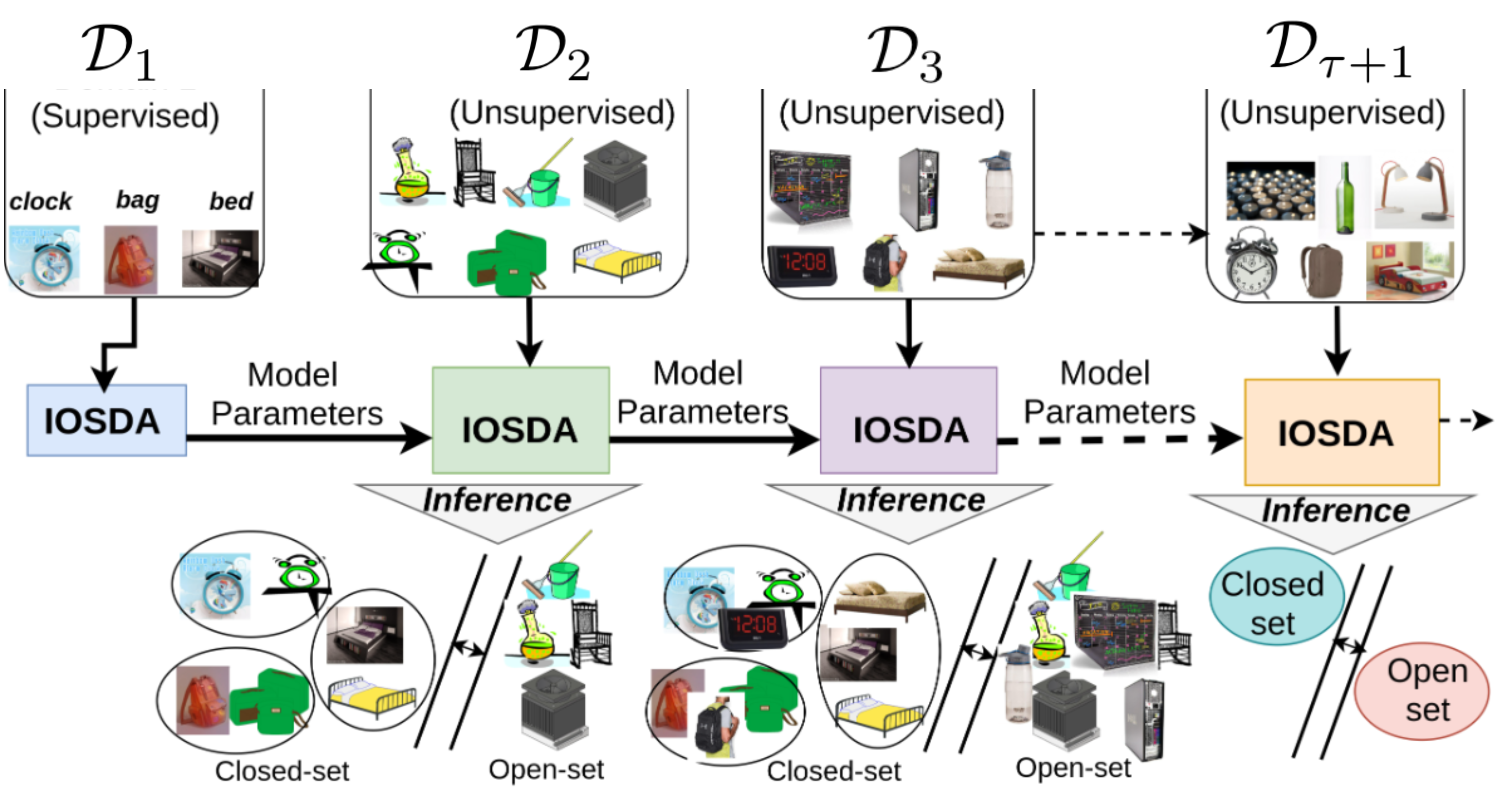
Sayan Rakshit, Hmrishav Bandyopadhyay, Nibaran Das,Biplab Banerjee Arxiv, 2024 paper bibTeX Catastrophic forgetting makes neural network models unstable when learning visual domains consecutively. The neural network model drifts to catastrophic forgetting-induced low performance of previously learnt domains when training with new domains. We illuminate this current neural network model weakness and develop a forgetting-resistant incremental learning strategy. Here, we propose a new unsupervised incremental open-set domain adaptation (IOSDA) issue for image classification. Open-set domain adaptation adds complexity to the incremental domain adaptation issue since each target domain has more classes than the Source domain. In IOSDA, the model learns training with domain streams phase by phase in incremented time. Inference uses test data from all target domains without revealing their identities. |
|
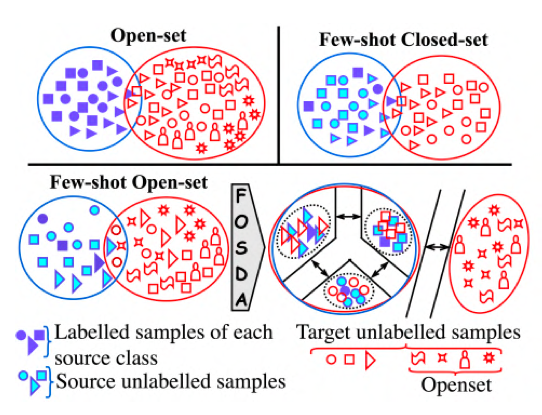
Sayan Rakshit, Balasubramanian S, Hmrishav Bandyopadhyay, Piyush Bharambe, Sai Nandan Desetti,Biplab Banerjee, Subhasis Chaudhuri CVPRw, 2022 paper bibTeX The notion of closed-set few-shot domain adaptation (FSDA) has been introduced where limited supervision is present in the source domain. However, FSDA overlooks the fact that the unlabeled target domain may contain new classes unseen in the source domain. To this end, we introduce the novel problem definition of few-shot open-set DA (FosDA) where the source domain contains few labeled samples together with a large pool of unlabeled data, and the target domain consists of test samples from the known as well as new categories. |
|
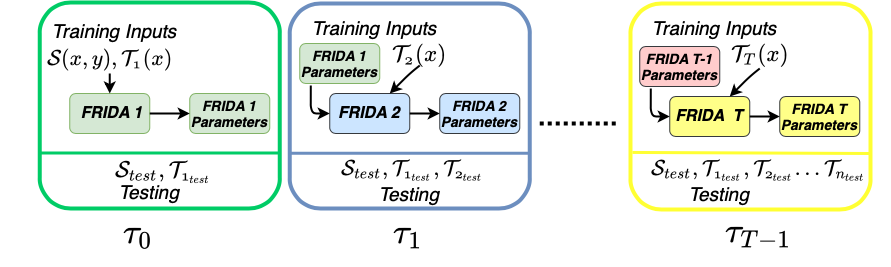
Sayan Rakshit, Anwesh Mohanty, Ruchika Chavhan,Biplab Banerjee, Gemma Roig, Subhasis Chaudhuri CVIU, 2022 paper bibTeX We tackle the novel problem of incremental unsupervised domain adaptation (IDA) in this paper. We assume that a labeled source domain and different unlabeled target domains are incrementally observed with the constraint that data corresponding to the current domain is only available at a time. The goal is to preserve the accuracies for all the past domains while generalizing well for the current domain. |
|
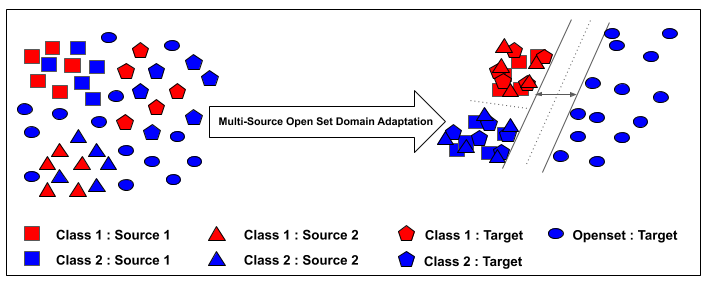
Sayan Rakshit, Dipesh Tamboli, Pragati Shuddhodhan Meshram,Biplab Banerjee, Gemma Roig, Subhasis Chaudhuri ECCV, 2020 paper bibTeX We introduce a novel learning paradigm of multi-source openset unsupervised domain adaptation (MS-OSDA). Recently, the notion of single-source open-set domain adaptation (SS-OSDA) which considers the presence of previously unseen open-set (unknown) classes in the target-domain in addition to the source-domain closed-set (known) classes has drawn attention. In the SS-OSDA setting, the labeled samples are assumed to be drawn from the same source. Yet, it is more plausible to assume that the labeled samples are distributed over multiple sourcedomains, but the existing SS-OSDA techniques cannot directly handle this more realistic scenario considering the diversities among multiple source-domains. |
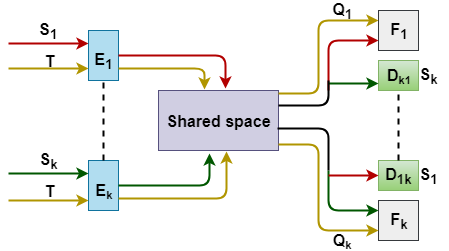
|
Sayan Rakshit, Biplab Banerjee, Gemma Roig, Subhasis Chaudhuri GCPR, 2019 paper bibTeX We address the problem of multi-source unsupervised domain adaptation (MS-UDA) for the purpose of visual recognition. As opposed to single source UDA, MS-UDA deals with multiple labeled source domains and a single unlabeled target domain. Notice that the conventional MS-UDA training is based on formalizing independent mappings between the target and the individual source domains without explicitly assessing the need for aligning the source domains among themselves. |
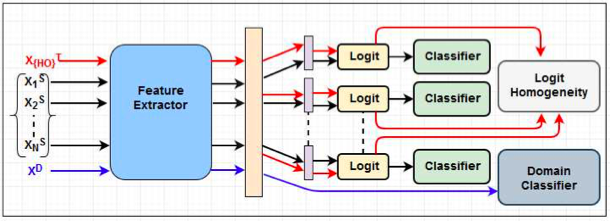
|
Sayan Rakshit, Ushasi Chaudhuri,Biplab Banerjee, Gemma Roig, Subhasis Chaudhuri CVPRw, 2019 paper bibTeX In unsupervised deep domain adaptation (DA), the use of adversarial domain classifiers is popular in learning a shared feature space which reduces the distributions gap for a pair of source (with training data) and target (with only test data) domains. In the new space, a classifier trained on source training data is expected to generalize well for the target domain samples |
News |
Work Experience |
|
Templet credit here
|